
Mastering Data Engineering with Apache Spark, Delta Lake, and the Lakehouse Paradigm

In the ever-evolving landscape of Big Data, data engineering plays a pivotal role in harnessing the power of vast and complex datasets. Apache Spark, a lightning-fast distributed computing engine, has emerged as a cornerstone of modern data engineering pipelines. Coupled with Delta Lake, a revolutionary storage layer that unifies the best of data lakes and data warehouses, Apache Spark empowers data engineers to manage, transform, and analyze their data with unprecedented agility and efficiency.
4.4 out of 5
| Language | : | English |
| File size | : | 54566 KB |
| Text-to-Speech | : | Enabled |
| Screen Reader | : | Supported |
| Enhanced typesetting | : | Enabled |
| Print length | : | 480 pages |
The Lakehouse architecture, a visionary concept that seamlessly blends the strengths of data lakes and data warehouses, has further revolutionized the data management landscape. By bridging the gap between raw data storage and structured data processing, the Lakehouse enables organizations to unlock the full potential of their data, empowering them with a single, unified platform for all their data needs.
Apache Spark: The Foundation of Modern Data Engineering
Apache Spark has swiftly become the de facto standard for distributed data processing. Its lightning-fast in-memory computation engine, capable of processing vast datasets with blazing speed, has made it a go-to solution for demanding data engineering tasks.
Spark's extensive ecosystem of libraries and APIs empowers data engineers to tackle a wide range of tasks, including data ingestion, data transformation, machine learning, and interactive data analysis. Its intuitive programming interface makes it accessible to both seasoned professionals and those new to the field.
Delta Lake: Unifying the Best of Data Lakes and Data Warehouses
Delta Lake, an open-source storage layer built on top of Apache Spark, represents a groundbreaking innovation in data management. It seamlessly unifies the best features of data lakes, such as unlimited data storage and schema flexibility, with the robust data management capabilities of data warehouses, including ACID transactions, data versioning, and sophisticated query optimization.
With Delta Lake, data engineers can enjoy the scalability and cost-effectiveness of data lakes while leveraging the advanced data management capabilities typically found in data warehouses. This convergence of strengths enables organizations to unlock the full potential of their data, extracting actionable insights from both structured and unstructured data sources.
The Lakehouse Paradigm: A Unified Platform for All Data Needs
The Lakehouse architecture, an ingenious concept that harmoniously blends the strengths of data lakes and data warehouses, has emerged as the next frontier in data management. By bridging the gap between raw data storage and structured data processing, the Lakehouse empowers organizations to eliminate data silos and gain a comprehensive view of their data.
With the Lakehouse paradigm, data engineers can store all their data, regardless of its format or structure, in a single, unified platform. This enables them to perform a wide range of data engineering and analytics tasks on a single, cohesive dataset, eliminating the need for complex data integration and transformation processes.
Data Engineering with Apache Spark, Delta Lake, and the Lakehouse: A Comprehensive Guide
Leveraging Apache Spark, Delta Lake, and the Lakehouse architecture, data engineers can revolutionize their data management and analytics practices. This comprehensive guide will provide you with an in-depth understanding of the fundamentals and best practices of data engineering in this modern era.
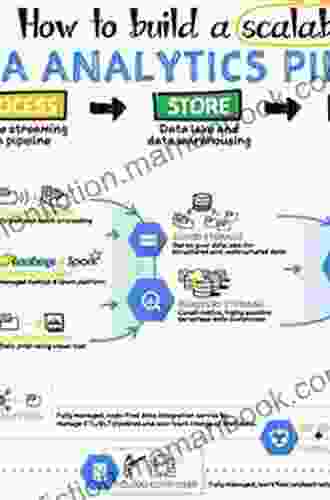
1. Data Ingestion: Seamlessly Unifying Diverse Data Sources
With Apache Spark and Delta Lake, data engineers can effortlessly ingest data from a wide variety of sources, including structured databases, unstructured data files, streaming data sources, and even cloud storage platforms.
Spark's powerful data connectors and Delta Lake's schema-on-read capability make it easy to integrate data from diverse sources, ensuring a unified and comprehensive view of your data.
2. Data Transformation: Efficiently Shaping and Refining Your Data
Once your data is ingested, Apache Spark provides a comprehensive suite of data transformation operators, allowing you to cleanse, enrich, and restructure your data to meet your specific needs.
With Spark's in-memory processing capabilities and Delta Lake's ACID transactions, you can perform complex transformations with confidence, ensuring data integrity and consistency.
3. Data Analytics: Unlocking Actionable Insights from Your Data
Apache Spark empowers data engineers to perform advanced data analytics on both structured and unstructured data, enabling them to extract meaningful insights and make informed decisions.
Spark's machine learning library and Delta Lake's optimized query performance make it possible to build sophisticated machine learning models and perform interactive data analysis on massive datasets.
4. Data Management: Ensuring Data Quality and Governance
Apache Spark and Delta Lake provide robust data management capabilities, enabling data engineers to maintain data quality and ensure data governance throughout the data lifecycle.
Delta Lake's ACID transactions, data versioning, and schema enforcement ensure data integrity, while Spark's data quality tools help identify and rectify data anomalies.
5. Data Security: Protecting Your Data Assets
Apache Spark and Delta Lake prioritize data security, offering robust features to protect your sensitive data from unauthorized access and cyber threats.
Spark's access control mechanisms and Delta Lake's encryption capabilities ensure that your data remains secure throughout its lifecycle.
Case Studies: Real-World Success Stories
Organizations across a wide range of industries are leveraging Apache Spark, Delta Lake, and the Lakehouse paradigm to revolutionize their data engineering and analytics practices.
From financial institutions leveraging real-time data analytics to improve fraud detection to healthcare organizations utilizing machine learning to enhance patient care, the Lakehouse paradigm is empowering organizations to unlock the full potential of their data.
Data engineering has evolved dramatically in the era of Big Data, and Apache Spark, Delta Lake, and the Lakehouse architecture are at the forefront of this transformation. By embracing these technologies, data engineers can harness the power of data to drive innovation, improve decision-making, and gain a competitive edge in today's data-driven world.
Whether you're a seasoned data engineer or just starting out in the field, this guide has provided you with a comprehensive understanding of the fundamentals and best practices of data engineering in the modern era. Embark on your journey to master Apache Spark, Delta Lake, and the Lakehouse paradigm, and unlock the full potential of your data.
4.4 out of 5
| Language | : | English |
| File size | : | 54566 KB |
| Text-to-Speech | : | Enabled |
| Screen Reader | : | Supported |
| Enhanced typesetting | : | Enabled |
| Print length | : | 480 pages |
Do you want to contribute by writing guest posts on this blog?
Please contact us and send us a resume of previous articles that you have written.
 Top Book
Top Book Novel
Novel Fiction
Fiction Nonfiction
Nonfiction Literature
Literature Paperback
Paperback Hardcover
Hardcover E-book
E-book Audiobook
Audiobook Bestseller
Bestseller Classic
Classic Mystery
Mystery Thriller
Thriller Romance
Romance Fantasy
Fantasy Science Fiction
Science Fiction Biography
Biography Memoir
Memoir Autobiography
Autobiography Poetry
Poetry Drama
Drama Historical Fiction
Historical Fiction Self-help
Self-help Young Adult
Young Adult Childrens Books
Childrens Books Graphic Novel
Graphic Novel Anthology
Anthology Series
Series Encyclopedia
Encyclopedia Reference
Reference Guidebook
Guidebook Textbook
Textbook Workbook
Workbook Journal
Journal Diary
Diary Manuscript
Manuscript Folio
Folio Pulp Fiction
Pulp Fiction Short Stories
Short Stories Fairy Tales
Fairy Tales Fables
Fables Mythology
Mythology Philosophy
Philosophy Religion
Religion Spirituality
Spirituality Essays
Essays Critique
Critique Commentary
Commentary Glossary
Glossary Bibliography
Bibliography Index
Index Table of Contents
Table of Contents Preface
Preface Introduction
Introduction Foreword
Foreword Afterword
Afterword Appendices
Appendices Annotations
Annotations Footnotes
Footnotes Epilogue
Epilogue Prologue
Prologue David Black
David Black Winter Travers
Winter Travers John North
John North Don Padilla
Don Padilla Mary Ann Littrell
Mary Ann Littrell Vinicio Sanchez
Vinicio Sanchez Paula Marantz Cohen
Paula Marantz Cohen James Swallow
James Swallow Osip Mandelstam
Osip Mandelstam Dancing Dolphin Patterns
Dancing Dolphin Patterns Scott M Rose
Scott M Rose Margo Jefferson
Margo Jefferson Upton Sinclair
Upton Sinclair Brad Smith
Brad Smith Brittany Fichter
Brittany Fichter Julianne Bosch
Julianne Bosch Laurence M Ball
Laurence M Ball Peter Frase
Peter Frase Dee Watson
Dee Watson Jessika Klide
Jessika Klide
Light bulbAdvertise smarter! Our strategic ad space ensures maximum exposure. Reserve your spot today!










 Dan HendersonFollow ·13.6k
Dan HendersonFollow ·13.6k John UpdikeFollow ·2.5k
John UpdikeFollow ·2.5k Finn CoxFollow ·12.5k
Finn CoxFollow ·12.5k Allan JamesFollow ·12.4k
Allan JamesFollow ·12.4k Octavio PazFollow ·12.7k
Octavio PazFollow ·12.7k Henry HayesFollow ·15k
Henry HayesFollow ·15k Gabriel HayesFollow ·6.5k
Gabriel HayesFollow ·6.5k Jermaine PowellFollow ·19k
Jermaine PowellFollow ·19k

 William Shakespeare
William Shakespeare
 Steve Carter
Steve CarterUnveiling the Rich Theatrical Tapestry of Russia: A...
Origins and Early...

 Frank Butler
Frank ButlerOn Talking Terms With Dogs: Calming Signals and the...
For centuries, dogs have...

 Ivan Turner
Ivan Turner
 Leo Tolstoy
Leo TolstoyThe Inside Guide to Applying and Succeeding in...
Applying to...

 Cole Powell
Cole PowellThe Political Economy of Global Finance, Farming and...
The global...
4.4 out of 5
| Language | : | English |
| File size | : | 54566 KB |
| Text-to-Speech | : | Enabled |
| Screen Reader | : | Supported |
| Enhanced typesetting | : | Enabled |
| Print length | : | 480 pages |
